
ADsP 35회 기출 공부
1. 다음 중 데이터 분석 알고리즘으로 부당한 피해를 보는 사람을 방지하기 위한 업무를 수행하는 직업은 무엇인가?
① 데이터 엔지니어
② 데이터 분석가
③ 데이터 아키텍처
④ 알고리즈미스트
| 알고리즈미스트: 데이터 사이언티스트, 데이터 분석가, 인공지능 전문가 등이 만들어낸 알고리즘으로 부당한 피해를 보는 사람을 방지하기 위해서 생겨난 직업으로 이들이 만들어 낸 알고리즘을 해석하여 피해를 입은 사람을 구제하는 전문가 |
2. 다음 중 빅데이터의 영향에 대해 올바르지 않은 것은?
① 산업 전체의 생산성이 향상되었다.
② 사물인터넷이 발달할 수 있는 기반을 제공하였다.
③ 추천 서비스의 질이 향상되었다.
④ 사회 변화를 추정, 각종 재해 관련 정보 추출 및 예측이 가능해졌다.
| 사물인터넷(IoT)은 빅데이터가 등장하기 전부터 존재하던 개념으로 빅데이터가 사물인터넷의 기반을 제공한 것은 아니다. |
3. 다음 중 빅데이터의 위기요인과 통제방안에 대한 내용과 관련이 없는 것은?
① 사생활 침해
② 데이터 오용
③ 책임원칙의 훼손
④ 데이터 변화 관리
| - 사생활 침해: 정보 제공자의 동의제에서 정보 사용자의 책임제로 - 책임원칙의 훼손: 결과 기반 책임 원칙 고수 - 데이터 오용: 알고리즘 접근 권한 허용 |
4. 다음 중 사용자와 데이터베이스 중간에 위치하여 사용자의 요구사항에 따라 데이터베이스를 관리하는 소프트웨어는 무엇인가?
① RPA
② DBMS
③ SQL
④ ERD
| DBMS(DataBase Management System): 다수의 사용자들이 데이터베이스 내의 데이터를 접근할 수 있도록 해주는 소프트웨어 도구의 집합이다. DBMS는 사용자 또는 다른 프로그램의 요구를 처리하고 적절히 응답하여 데이터를 사용할 수 있도록 해준다. |
5. 다음 중 빅데이터 기술 활용에 관련된 설명으로 거리가 먼 것은?
① 적시에 필요한 정보를 획득하고 자유롭게 가공하여 기회비용을 절약할 수 있다.
② 기업의 원가절감, 제품 차별화, 기업 활동의 투명성 제공 등에 활용될 수 있다.
③ 공공의 이익을 위해 개인의 정보는 자유롭게 활용될 수 있다.
④ 미래 사회를 대비해 법적 제도 및 거버넌스 시스템, 미래 성장 전략 등에 대한 정보를 제공한다.
| 개인의 정보는 동의 없이 활용될 수 없다. |
6. 다음 중 데이터베이스와의 통신을 위해 고안된 언어는 무엇인가?
① Python
② Java
③ R
④ SQL
| SQL(Structured Query Language): 데이터베이스에서 데이터를 추출하고 조작하는 데에 사용하는 데이터 처리 언어 |
7. 다음 중 데이터 사이언티스트의 필요 역량으로 적절하지 않은 것은?
① 네트워크 최적화 능력
② 고객과의 공감 능력
③ 데이터 처리 기술
④ 비즈니스 도메인에 대한 이해
| ①번은 네트워크 엔지니어의 필요 역량이다. |
8. 다음 중 사생활 침해 방지 기술에 해당하는 것으로 개인 식별 정보를 알아볼 수 없는 형태로 변환하는 것과 가장 유사한 것은?
① 데이터 범주화
② 데이터 마스킹
③ 총계처리
④ 데이터 값 삭제
| 데이터 마스킹이란 [홍길동]을 [홍**]으로 바꾸는 등의 과정을 말한다. |
9. 문자, 기호, 음성 영상 등 상호간에 관계를 갖는 다수의 객체 및 컨텐츠 등을 한곳의 저장소에 체계적으로 수집, 축적하여 모아논 것으로 다양한 용도와 방법으로 활용될 수 있는 정보의 집합체를 무엇이라 하는가?
정답 : 데이터베이스
10. 최적화 메커니즘의 일종으로 ‘최대의 시청률을 얻기 위해서는 어떠한 프로그램을 어떤 시간대에 방송해야하는가’라는 질문에 답을 주기 위한 빅데이터 활용 테크닉을 무엇이라 하는가?
정답 : 유전 알고리즘
11. 다음 중 데이터 거버넌스의 구성요소가 아닌 것은?
① 원칙
② 방법
③ 조직
④ 프로세스
| 원칙, 조직, 프로세스 (원조 프로세스 암기) |
12. 다음 중 분석 마스터 플랜의 과제 우선순위 결정과 관련된 내용으로 적절하지 않은 것은?
① ROI 관점에서의 분석 과제 우선순위 평가 기준은 시급성과 난이도로 나누어서 살펴본다.
② 난이도 판단 기준은 데이터의 양/데이터의 유형/데이터의 변화 속도 등이 있다.
③ 시급성의 판단 기준은 전략적 중요도가 핵심이다.
④ Value는 투자 비용 요소이다.
| 투자 비용 요소: Volume(규모), Variety(다양성), Velocity(속도) 비즈니스 요소: Value(가치) |
13. 다음 중 분석 과제 우선순위 선정 시 난이도와 시급성 모두를 고려하였을 때 우선적으로 추진해야하는 분석 과제는 무엇인가?
① 난이도: 쉬움, 시급성: 현재
② 난이도: 어려움, 시급성: 현재
③ 난이도: 쉬움, 시급성: 미래
④ 난이도: 어려움, 시급성: 미래
| 상식적으로 쉬우면서 지금 당장 필요한걸 우선적으로 해야한다. |
14. 다음 중 분석 과제 도출 방법 중 상향식 접근 방식의 절차로 알맞은 것은?
① 프로세스 분류 → 프로세스 흐름 분석 → 분석요건 식별 → 분석요건 정의
② 프로세스 분류 → 분석요건 식별 → 프로세스 흐름 분석 → 분석요건 정의
③ 프로세스 흐름 분석 → 프로세스 분류 → 분석요건 식별 → 분석요건 정의
④ 프로세스 흐름 분석 → 분석요건 식별 → 프로세스 분류 → 분석요건 정의
| 암기 |
15. 다음 중 기업의 분석 도입 수준을 파악하기 위한 분석 준비도와 관계가 적은 것은?
① 분석 인력 및 조직
② 분석 기법
③ 분석 목표
④ 분석 데이터
| IT인프라, 분석 문화, 분석 데이터, 분석 기법, 분석 인력, 분석 업무 파악 (IT문데기인파 암기) |
16. 다음 중 데이터 분석을 위한 조직 구성 중 분석 조직 인력들을 현업부서로 배치하여 신속한 업무 수행이 가능한 조직 구조를 무엇이라 하는가?
① 집중형 조직 구조
② 기능 중심 구조
③ 분산 조직 구조
④ 혼합 조직 구조
| 현업부서로 배치하는 것은 분산 조직 구조 |
17. 다음 중 빅데이터 분석 기획 단계에서 프로젝트 위험 계획 수립 시 잠재된 위험에 대한 대응 방법으로 옳지 않은 것은?
① 관리
② 수용
③ 전이
④ 완화
| 회피, 전이, 완화, 수용 (회전완수 암기) |
18. 다음 중 데이터 거버넌스 체계의 단계들 중 메타데이터와 데이터 사전의 관리 원칙 수립과 관련된 단계는?
① 데이터 표준화
② 데이터 관리체계
③ 데이터 저장소 관리
④ 표준화 활동
| 관리 원칙 수립과 관련된 단계니까 데이터 관리체계라고 연관지어 생각하기 |
19. 문제가 주어지고 해답을 찾기 위한 방법으로 각 과정이 체계적이고 단계화 되어 수행되는 분석 과제 도출 방식은?
정답 : 하향식 접근법
20. 아래에서 설명하고 있는 분석 조직 구조는 무엇인가?
| - 별도의 독립적인 분석 전담 조직을 구성하여 회사 전사적인 분석 업무를 담당한다. - 전략적 중요도에 따라 전사적 차원에서 우선순위를 정해 추진 가능하다. - 일부 현업 부서와 분석 업무가 중복 또는 이원화가 될 가능성이 있다. |
정답 : 집중형 조직 구조
21. 다음 중 자기 조직화 지도(SOM)에 대한 설명으로 옳지 않은 것은?
① 비지도 학습의 일종이다.
② 입력층과 출력층 사이에 은닉층이 존재하여 효율적인 군집화가 가능하다.
③ 차원축소와 군집화가 동시에 수행되는 기법이다.
④ 출력 뉴런들은 승자 뉴런이 되기 위해 경쟁하는 승자 독식 구조이다.
| ②번은 신경망에 대한 설명이다. |
22. 다음 중 오분류표를 사용하여 특이도를 구하는 식으로 올바른 것은?

① TN/(FP+TN)
② TP/(TP+FN)
③ TP/(TP+FP)
④ (TP+TN)/(TP+FN+FP+TN)
| 정밀도(Precision): 예측을 P로 한 것 중에서 실제로 P인 비율 민감도(Sensitivity 또는 Recall): 실제로 P인 것 중에서 예측이 P인 비율 특이도(Specificity): 실제로 N인 것 중에서 예측이 N인 비율 |
23. 다음 중 의사결정나무에 대한 설명으로 적절하지 않은 것은?
① 비지도 학습으로 상향식 접근법을 이용한다.
② 구조가 단순하며 해석이 용이한 장점이 있다.
③ 목표변수의 유형(이산형, 연속형)에 따라 적용되는 알고리즘은 다르다.
④정지규칙, 가지치기 등을 통하여 분류나무를 최적화 할 수 있다.
| 의사결정나무는 지도 학습이며 하향식, 상향식과는 관계가 없다. |
24. 다음 중 회귀분석의 결정계수에 대한 설명으로 올바르지 않은 것은?
① 결정계수는 0에서 1사이의 값을 갖는다.
② 결정계수의 값이 클수록 회귀모형의 설명력은 높다.
③ 결정계수의 값은 회귀제곱합(SSR)/총제곱합(SST)의 값으로 계산된다.
④ 2개 이상의 독립변수가 활용될 때 단위의 차이로 발생할 수 있는 오차를 제거한 것이 수정된 결정계수이다.
| 독립변수의 개수가 많아지면 모형의 설명력과는 관계 없이 결정계수가 커지는 단점을 보완한 것이 수정된 결정계수이다. |
25. 다음 중 로지스틱 회귀모형에 대한 설명으로 옳지 않은 것은?
① 독립변수가 한 단위 증가할 때
② 오즈값에 로그함수를 사용하여 회귀분석을 수행한다.
③ 모형 검정에는 F 검정이 사용된다.
④종속변수가 범주형인 경우에 활용가능한 회귀분석 모형이다.
| 로지스틱 회귀분석은 카이제곱( |
26. 두 좌표 A, B에 대해서 맨해튼 거리를 바르게 계산 한 것은?
| A | B | |
| X | 160 | 165 |
| Y | 70 | 80 |
① 5
② 10
③ 15
④ 5√5
유클리드 거리: 맨해튼 거리: |
27. 다음 중 데이터 마이닝 프로세스를 올바르게 나열한 것은?
| (가) 목적 정의 (나) 데이터 준비 (다) 데이터 가공 (라) 데이터 마이닝 기법 적용 (마) 검증 |
① (가) - (나) - (다) - (라) - (마)
② (가) - (다) - (나) - (라) - (마)
③ (가) - (나) - (다) - (마) - (라)
④ (가) - (다) - (나) - (마) - (라)
| 암기 |
28. 다음 중 목표변수가 연속형인 회귀나무의 분류 기준값을 선택하는 기준으로 구성된 것은?
① F통계량, 분산 감소량
② F통계량, 엔트로피 지수
③ 엔트로피 지수, 지니 지수
④ 지니 지수, 분산 감소량
| 연속형인 회귀나무: F통계량, 분산 감소량 범주형인 회귀나무: 엔트로피 지수, 지니 지수 |
29. 아래는 확률분포 X의 확률분포표이다. 다음 중 그 설명이 잘못된 것은?
| X | 1 | 2 | 3 |
| 1/6 | 1/2 | 1/3 |
① 확률변수 X의 확률의 합은 반드시 1이다.
② 확률변수 x가 0일 확률은 0이다.
③ 확률변수 x가 1또는 2일 확률은 1/12이다.
④ 확률변수 x의 기댓값은 13/6이다.
| 1/6 + 1/2 = 2/3이다. |
30. 다음 중 혼합분포 군집의 특징으로 적절하지 않은 것은?
① 복잡한 형태를 가진 분포의 경우 선형 결합된 여러 개의 확률분포로 설명할 수 있다.
② 군집을 몇 개의 모수로 표현할 수 있으며, 각각의 군집은 확률분포로 나타내어진다.
③ 모수 추정에서 데이터가 커지면 군집수행을 위한 반복횟수가 커진다.
④ 군집의 크기가 작을수록 추정이 쉽고 정밀한 추정이 가능하다.
| 군집이 작을수록 추정이 어렵다. |
31. 다음 중 EM알고리즘을 사용한 혼합분포 모형의 결과에 대한 해석으로 잘못된 것은 무엇인가?

① 반복 횟수 2회 만에 로그 가능도함수가 최대가 됨을 알 수 있다.
② 로그 가능도 함수의 최댓값은 –1035보다 크다.
③ 2개의 정규분포가 혼합된 모형임을 알 수 있다.
④ summary 함수를 활용하여 두 분포의 평균과 표준편차 비율 정도를 알 수 있다.
| 반복 횟수 2회 이후에도 로그 가능도함수 값이 조금 더 증가한다. |
32. 아래의 확률변수 x의 기댓값을 바르게 계산한 것은?
| X | 1 | 2 | 3 | 4 |
| 1/8 | 1/4 | 1/4 | 3/8 |
① 20/8
② 21/8
③ 22/8
④ 23/8
| 기댓값: 1*(1/8) + 2*(1/4) + 3*(1/4) + 4*(3/8) = 23/8 |
33. 다음 중 홀드아웃에 대한 설명으로 올바른 것은 무엇인가?
① 전체 데이터를 학습데이터와 테스트 데이터 두 세트로 나누는 방법이다.
② 과대적합을 방지하기 위해 고안된 방안이다.
③ 회귀분석에서 다중공선성으로 인해 발생하는 문제를 해결하기 위해 고안된 방법이다.
④ 하나의 모형이 아닌 여러 개의 모형을 생성 및 조합하여 예측력이 높은 모형을 만드는 방법이다.
| ②번은 교차검증에 대한 내용이다. ③번은 주성분 분석에 대한 내용이다. ④번은 앙상블 학습에 대한 내용이다. |
34. 다음 중 입력신호를 받아 출력신호로 연결하기 위한 활성화 함수로 로지스틱 회귀모형에서 주로 사용하는 활성화 함수는?
① Softmax
② Relu
③ Sign
④ Sigmoid
| 로지스틱 회귀모형에서 주로 사용하는 활성화 함수는 시그모이드(Sigmoid) 함수이다. (다른 함수 정보는 구글에 검색) |
35. 다음 중 군집의 수를 미리 지정하지 않으며 탐색적 기법에 적합한 군집 방법은?
① 혼합분포 군집
② K means 군집
③ 계층적 군집
④ 다차원 척도법
| 계층적 군집은 덴드로그램을 그려서 군집화를 수행하며 군집의 수를 미리 지정하지 않아도 된다는 점과 고립된 군집을 쉽게 찾을 수 있다는 장점이 있다. |
36. 다음 중 선형 회귀 모형의 통계적 유의성 검증을 위해 사용하는 것은?
① F 통계량
② 결정계수
③ T 통계량
④ p-value
| 선형 회귀 모형의 유의성 검정에는 F검정을 사용하며 F 통계량을 계산한다. |
37. 다음 중 연관규칙 A → B일 때 지지도에 대한 식으로 올바른 것은?
① P(A ∩ B)
② P(B) / P(A ∩ B)
③ P(A) / P(A ∩ B)
④ P(A ∩ B) / P(A + B)
| 연관규칙 A → B일 때 지지도: P(A ∩ B), 신뢰도: P(B | A), 향상도: P(A ∩ B) / P(A)P(B) |
38. 다음 중 Lasso 회귀 모형의 정의에 대한 설명으로 올바른 것은?
① 가중치의 절대값의 합과 제곱합을 동시에 제약조건으로 갖는 모형이다.
② 일부 가중치 파라미터를 제한하지만 0이 아닌 0에 가깝게 만든다.
③ L2 penalty를 활용한다.
④ 가중치들의 절대값의 합을 최소화하는 것을 제약 조건으로 추가한다.
| ①번은 엘라스틱 넷(Elastic Net)에 대한 설명이다. ②, ③번은 릿지(Ridge) 회귀 모형에 대한 설명이다. |
39. 아래 산점도는 차량 392대의 연비(mpg)와 마력(horsepower)의 관계를 나타내고 있다. 다음 중 그 아래 산점도에 대한 설명으로 잘못된 것은?
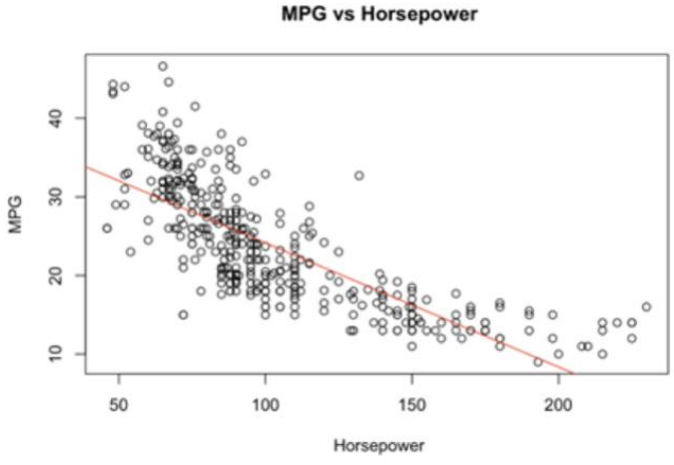
① 마력이 증가할 때 연비는 감소하는 경향이 있다.
② 위 데이터의 상관성을 알기 위해서는 스피어만 상관계수를 구하는 것이 바람직하다.
③ 두 변수는 뚜렷한 음의 상관관계를 보이고 있다.
④ 어느정도의 선형성을 보아 선형회귀모형을 통해 연비를 추정할 수 있다.
| 위의 데이터는 연속형 데이터이기 때문에 피어슨 상관계수를 구하는 것이 바람직하다. (스피어만은 순위 상관계수이다.) |
40. 다음 중 분류 모형에 대한 설명으로 적절한 것은?
① 과거부터 지금까지 발생된 현상들에 대해 특징을 찾고 새로운 데이터에 대한 분류 혹은 미래에 대한 예측을 위해 활용된다.
② 카탈로그 배열, 교차판매, 효율적인 마케팅 등을 위해 사용되는 기법이다.
③ 여러 자료들 사이의 유사성을 측정하고 유사한 자료들을 그룹화하여 각 그룹의 특성을 찾는 분석기법이다.
④ 일정 시간 간격으로 기록된 자료들에 대하여 특성을 파악하고 가까운 미래를 예측하는 분석방법이다.
| ②번은 연관분석이다. ③번은 군집분석이다. ④번은 시계열분석이다. |
41. 아래는 ISLR 패키지의 Default 데이터를 활용하여 회귀분석을 수행한 결과이다. 다음 중 그 결과를 잘못 해석한 것은?

① 로지스틱 회귀분석을 수행한 결과이다.
② 위 분석을 수행하는데 활용된 데이터는 10000개이다.
③ income은 default를 설명하는데 통계적으로 유의미한 변수이다.
④ balance는 default를 설명하는데 통계적으로 유의미한 변수이다.
| ①: family = "binomial" 이므로 로지스틱 회귀분석이 맞다. ②: 잔차 편차(Residual deviance)의 자유도는 ③: income의 z검정 유의확률은 0.71152로 유의수준 0.05 하에서 통계적으로 유의하지 않다. ④: balance의 z검정 유의확률은 2e-16으로 유의수준 0.05 하에서 통계적으로 유의하다. |
42. 다음 중 군집분석에 대한 설명으로 잘못된 것은?
① 군집분석은 이상치에 민감하다.
② 군집분석이 수행된 후에는 결과를 판단하기 위해 오분류표를 활용한다.
③ 각 객체간의 유사성을 판단하여 객체들을 몇 개의 집단으로 그룹화하는 기법이다.
④ 자기 조직화 지도는 군집분석이면서도 동시에 시각화가 가능한 기법이다.
| 오분류표는 분류분석에서 사용한다. |
43. 다음 중 시계열 분석에 대한 설명으로 잘못된 것은 무엇인가?
① 데이터가 추세를 보일 경우 차분을 통해 정상 시계열로 만들 수 있다.
② 시계열 데이터는 대부분 비정상 시계열이기 때문에 정상 시계열로 만든 후에 분석을 수행할 수 있다.
③ 시계열 그래프를 통해서 정상성 여부는 확인할 수 있으나 이상 여부는 확인할 수 없다.
④ 정상 시계열인 경우 평균값 주변에서 변동의 폭은 대체로 일정하다.
| 정상성 여부와 이상 여부 모두 확인 가능하다. |
44. 다음 중 연관분석에 대한 설명으로 옳지 않은 것은?
① 품목의 세분화가 많이 될수록 좋은 결과를 도출한다.
② 분석 대상이 되는 품목의 수가 증가하면 계산량은 기하급수적으로 증가한다.
③ 조건반응으로 A 라면 B이다 로 해석되어 누구나 쉽게 결과를 이해할 수 있다.
④ 목적변수가 없으므로 데이터 탐색에 유용하다.
| 품목의 세분화가 너무 많으면 계산량이 기하급수적으로 증가하여 좋은 결과를 도출 할 수 없다. |
45. 차원축소 기법 중 하나로, 객체들 사이의 유사성, 비유사성을 2차원 혹은 3차원 공간상에 점으로 표현하여 개체 사이 군집을 시각적으로 표현하는 기법은?
정답 : 다차원 척도법
46. 군집분석에서 두 군집간의 거리를 측정하기 위한 방법으로 각 군집간의 가장 먼 데이터를 두 군집의 거리로 정의하는 방법은?
정답 : 최장연결법
47. 설명변수 선택 방법 중에서 독립변수 후보를 모두 포함한 모형에서 출발해 제곱합의 기준으로 가장 적은 영향을 주는 변수부터 하나씩 제거하면서 더 이상 유의하지 않은 변수가 없을 때까지 설명변수를 제거하는 모형은?
정답 : 후진 제거법
48. 원천 데이터를 랜덤하게 두 분류로 분리하여 교차검정을 실시하는 방법으로 하나는 모형 학습 및 구축을 위한 훈련용 자료로, 다른 하나는 성과 평가를 위한 검증용 자료로 사용하는 방법은?
정답 : 홀드 아웃
49. 다단위 시간이나 단위 공간에서 특정 사건이 몇 번 발생하는지를 표현하는 기댓값과 분산이 같을 확률분포는 무엇인가?
정답 : 포아송 분포
50. P(A)=0.4, P(B)=0.3이고, 사건 A와 사건 B가 독립사건일 경우 P(B|A)를 계산하시오.
정답 : 0.3
| 두 사건이 독립이면 P(A ∩ B) = P(A)P(B) 따라서, P(B|A) = P(B ∩ A) / P(A) = P(B)P(A) / P(A) = P(B) = 0.3 |